
浏览器解析过程
用户输入网址或者点链接
通过DNS找到IP
通过TCP发起请求,三次握手
发起请求(get,post…)
获取HTTP请求的回执,拿到header,content
拿到Content开始解析
解析dom树
解析ccs树
形成 renderTree
执行javascript
回流,计算出所有dom位置
重绘,绘制所有dom
交给 GPU
这是我理解的浏览器解析过程,根据文档详细学习一下
1. DNS 查询
浏览器向名称服务器发起 DNS 查询请求,最终得到一个 IP 地址
一般是一层一层网上找
浏览器缓存 => 计算机缓存 => 本地hosts文件 => DNS解析器 => 根域名服务器 => 顶级域名服务器 => 权威域名服务器.
其实如果到了本地hosts文件这一步,就脱离了我们控制了。
我尝试在 edge 浏览器 edge://flags 中找dns选项,可惜没有找到,倒是在 firfox 中找到了选项
- network.dnsCacheExpiration:此配置项控制 DNS 缓存的过期时间,以秒为单位。默认值为 60 秒。您可以根据需求进行调整。
- network.dnsCacheEntries:此配置项指定 DNS 缓存的最大条目数。默认值为 400。您可以根据需求进行调整。
- network.dnsCacheExpirationGracePeriod:此配置项定义了 DNS 缓存的过期时间延迟,以秒为单位。默认值为 60 秒。您可以根据需求进行调整。
计算机缓存
- Windows操作系统:DNS缓存时间可以在注册表中进行设置,路径为HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Dnscache\Parameters,其中有一个键名为 MaxCacheTtl,表示最大缓存时间。
- macOS操作系统:DNS缓存时间可以通过 sudo killall -HUP mDNSResponder 命令来刷新,刷新后的缓存时间由操作系统自动决定。
- Linux操作系统:DNS缓存时间可以在 /etc/resolv.conf 文件中进行配置,其中的 options 部分可以设置缓存时间。
hosts 每个操作系统都有,自己设置即可
2. TCP 握手 & TLS 协商
这个涉及到 http 建立请求的三次握手的问题,以及https协商的问题,可以简单理解为请求,不了解细节
经过 8 次往返,浏览器终于可以发出请求。
- 第一次握手(SYN):客户端向服务器发送一个同步(SYN)请求,表示客户端想要建立连接。这个请求包含一个随机生成的初始序列号(ISN)用于后续的数据传输。
- 第二次握手(SYN + ACK):服务器收到客户端的请求后,会发送一个同步和确认(SYN + ACK)响应。服务器响应中包含了确认号(ACK)字段,用于确认客户端的初始序列号,并且也包含了自己生成的初始序列号(ISN)。
- 第三次握手(ACK):客户端收到服务器的响应后,会向服务器发送一个确认(ACK)消息,确认服务器的初始序列号。
https
- 客户端发起连接:客户端向服务器发起HTTPS请求。URL中的协议头为”https://“,默认使用端口号443进行连接。
- 服务器证书验证:服务器将自己的数字证书发送给客户端。该证书包含了服务器的公钥以及其他身份验证信息。
- 客户端验证证书:客户端收到服务器的证书后,会进行证书的验证过程。这包括检查证书的合法性、是否过期、是否由受信任的证书颁发机构(CA)签发等。
- 密钥交换:如果服务器的证书验证通过,客户端会生成一个用于加密通信的随机对称密钥。该密钥用服务器的公钥进行加密后发送给服务器。
- 服务器解密密钥:服务器使用自己的私钥解密客户端发送的密钥,获取到对称密钥。
- 数据传输:客户端和服务器使用对称密钥对后续的数据进行加密和解密,确保数据在传输过程中的机密性和完整性。
3. tcp慢启动
慢启动是我第一次了解的概念,在不了解实现细节的前提下,大概是这样的
每个人的网络,带宽情况不一样,发送能力和接收能力不一样,
假设两台机器 A,B,
A 接收能力 30, 发送能力 50
B 接收能力 30, 发送能力 50.
那么这个时候 B => A, A是会丢包的,因为他无法一次性接收50,他最大是30
因为不清楚实时的管道传输能力,于是在刚开始传送数据的时候,从一个很小的单位值做尝试;在之后的传送过程中,逐渐翻倍增大传送数据单位值。遇到失败的情况,就立马减小传送数据单位值。
4. 构建 DOM 树
写过html就知道,它是一种标记语言,就是一系列的标签组成,可以形成树形结构。
我们请求以后收到字节 => 字符串 => token => node => dom
<html> 根节点,以他为起点开始解析,最后形成一个dom树。
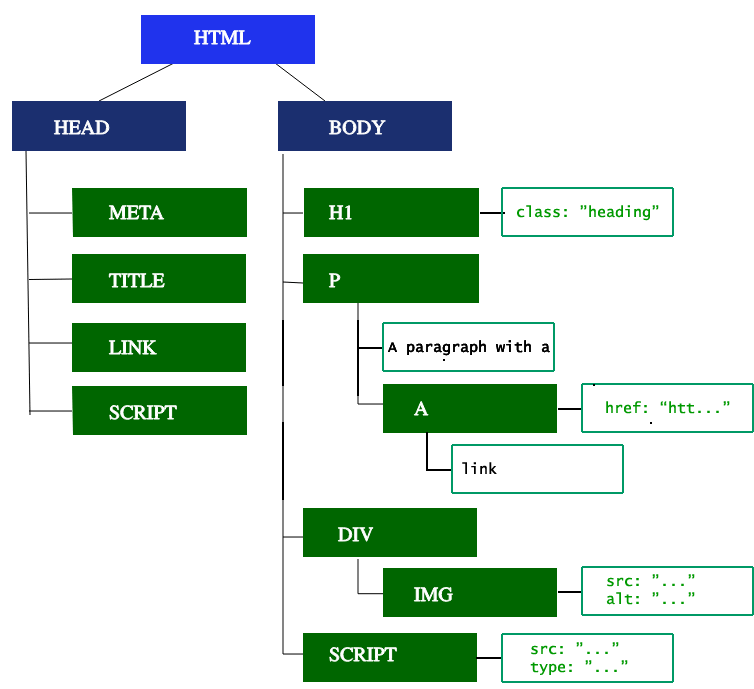
类似于上面这种结构。
5. script 阻塞
当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。当遇到一个 CSS 文件时,解析也可以继续进行,但是对于 script 标签(特别是没有 async 或者 defer 属性的)会阻塞渲染并停止 HTML 的解析。尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈。
script 标签明确会阻止解析, 但是也有区别
1 | <div id="test_one">content one</div> |
这样就很明确是执行完成 script 以后,再继续解析,但是有区别,上面这种写法是直接
1 | content one |
如果我新建一个 parse.js, 并且修改代码
1 | <div id="test_one">content one</div> |
那么就是先出现 content one, 然后等 js 执行完成, 再出现 content two。
阻塞渲染并不是页面不渲染,如果页面非要等到js加载执行完毕之后再渲染,那用户等待时间也太长了。浏览器的设计肯定会尽早让用户看到页面,因此遇到 script 标签时,会触发一次Paint,浏览器会将 script 标签之前的元素渲染出来。
有点类似于强制同步布局, 就是因为 javascript 的执行,导致了强行跳过或者提前了步骤。
经过测试,script 在不加 async or defer 的前提下, 都会阻止解析,在 header,inline script 中会执行所有 js 后继续解析,如果是在 body 中引入 js,会触发 Paint.
6. 预加载扫描器
和 html解析器,有一个并行的预解析器。
当浏览器进行 HTML 解析时,它可以启动一个额外的预测性 HTML 解析器。这个预测性解析器与普通的 HTML 解析器类似,遵循相同的规则和树构建算法。但是,预测性解析器不会影响普通解析器的状态和文档本身。
不用去纠结他怎么解析的,但是需要知道他关注哪些节点
A element.base
A element whose attribute is in the Content security policy state.metahttp-equiv
A element whose attribute is an ASCII case-insensitive match for “”.metanamereferrer
A element whose attribute is an ASCII case-insensitive match for “”. (This can affect whether a media query list matches the environment.) [CSSDEVICEADAPT]metanameviewport
我很疑惑,似乎没有link or script,或者 image 之类的,但是查寻文章都说包含了 link 和 script.
对于带有 async 属性的 script 标签,浏览器通常不会进行预解析,而是并行加载和执行。对于带有 defer 属性的脚本,浏览器可能会预解析,但不会立即执行,而是在文档解析完成后按顺序执行。
先知道概念即可,后续可以做实验。
7. CSSDOM
DOM 和 CSSOM 是两棵树。它们是独立的数据结构。浏览器将 CSS 规则转换为可以理解和使用的样式映射。浏览器遍历 CSS 中的每个规则集,根据 CSS 选择器创建具有父、子和兄弟关系的节点树。
在浏览器解析 HTML 文档时,遇到外部 CSS 样式表(通过 link 标签引入)会触发 CSSOM 的构建。浏览器会异步下载并解析外部样式表,生成对应的 CSSOM 树。同时,浏览器会继续解析 HTML,构建 DOM 树。这意味着 CSSOM 的构建和 DOM 树的构建是同时进行的,互不阻塞。
然而,在解析过程中,如果遇到内联的 style 标签或者内联样式属性,浏览器会立即处理它们,生成对应的 CSSOM 节点,并将其添加到 CSSOM 树中。因此,在遇到内联样式时,CSSOM 的构建可能会在 DOM 树构建之前完成。
8. JavaScript 编译
JavaScript 被解释、编译、解析和执行。脚本被解析为抽象语法树。一些浏览器引擎使用抽象语法树并将其传递到解释器中,输出在主线程上执行的字节码
9. 构建辅助功能树
10. render tree
DOM 和 CSSOM 组合成一个 Render 树, 计算样式树或渲染树从 DOM 树的根开始构建,遍历每个可见节点
需要注意的是 display: none 是不会渲染在 render tree 当中的,但是 visibility: hidden 是会出现的。
在资料中说明了哪些是默认包含 display:none, 比如 script.
render tree 就是 dom树 每个节点都匹配上 ccsom。
11. Layout(定位)
也就是回流,第一次叫定位
渲染树上运行布局以计算每个节点的几何体。布局是确定呈现树中所有节点的宽度、高度和位置,以及确定页面上每个对象的大小和位置的过程。回流是对页面的任何部分或整个文档的任何后续大小和位置的确定。
12. 绘制
也就是重绘。
这边有一个分层的机制
绘制可以将布局树中的元素分解为多个层。将内容提升到 GPU 上的层(而不是 CPU 上的主线程)可以提高绘制和重新绘制性能。有一些特定的属性和元素可以实例化一个层,包括 video 和 canvas,任何 CSS 属性为 opacity 、3D transform、will-change 的元素,还有一些其他元素。这些节点将与子节点一起绘制到它们自己的层上,除非子节点由于上述一个(或多个)原因需要自己的层。
然后合并给GPU。
分层确实可以提高性能,但是它以内存管理为代价,因此不应作为 web 性能优化策略的一部分过度使用。
13. 交互
文档中提出了如果 javascript 如果很大或者下载时间很长,可能会导致交互无法使用。
主线程在这段时间内完全被占用,对单击事件或屏幕点击没有响应。
14. javascript 流程。
一般来说
JavaScript的加载、解析与执行会阻塞文档的解析,也就是说,在构造DOM时,HTML解析器若是遇到了JavaScript,那么它会暂停文档的解析,将控制权交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复继续解析文档。
理论上是这样的,但是有一个是预解析器存在,javascript的加载和解析是和 dom树解析是并行的
我做了一个简单测试
1 | <body> |
结果是于加载完成了 parse.js, 但是执行顺序还是顺序的。
15. link
理论上,既然样式表不改变 DOM 树,也就没有必要停下文档的解析等待它们,
然而,存在一个问题,JavaScript 脚本执行时可能在文档的解析过程中请求样式信息,
如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题。所以如果浏览器尚未完成 CSSOM 的下载和构建,
而我们却想在此时运行脚本,那么浏览器将延迟 JavaScript 脚本执行和文档的解析,直至其完成 CSSOM 的下载和构建。
也就是说,在这种情况下,浏览器会先下载和构建 CSSOM,然后再执行 JavaScript,最后再继续文档的解析。
14. 总结
DNS查寻 => TCP => HTTP => 与服务器交互(获取字节) => 解析 => 解析dom树(如何解析到CSS,并行解析cssom) => 合并生成 render tree => 定位 => 绘制
具体性能优化后面再看